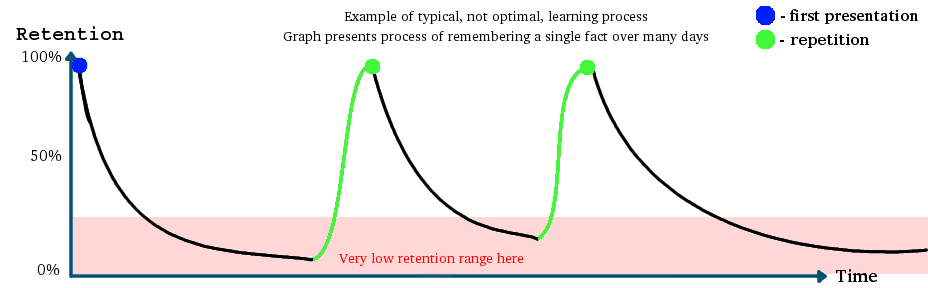
(Retention = proportion of remembered knowledge)
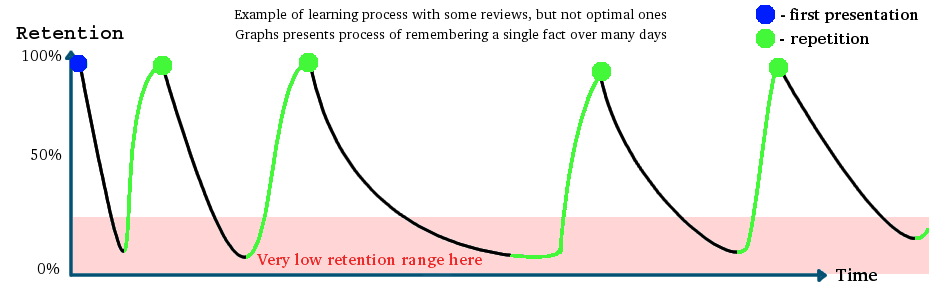
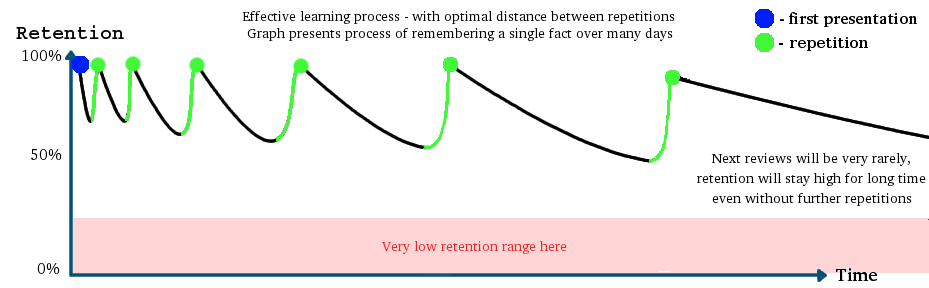
Back to Index
Definitions:
The ANN in MemAid (since version 0.4.0) uses 4 inputs and 1 output.
ANN requires the minimum data necessary to compute/approximate the next item interval
The ANN is pre-trained, but will learn and adapt itself to a particular user in a simple way. Every item remembers some basic history about itself (e.g. last_interval_ann_gave, real_last_interval, last_grade). On review, after computing a new interval, we feed the new data to the ANN. We add the following to the "ANN training data":
Inputs are:FACTOR is equal to:
First problem with using an ANN to schedule repetitions is to decide what data the ANN needs, and to predict an item's next optimal repetition date. Of course, the primary factor is the grade (1). The ANN needs the current grade, i.e. how well you remember an item now.
Now think about the forgetting curve: obviously, the ANN also needs :
It's very easy to collect this data - every item should keep own history: date of last repetition and number of repetitions.
But it's not everything.
We tend to remember some things better, some not.
So there is a "difficulty" factor.
How can the ANN know what is easy to remember, and what is not?
Well, if you are forgetting an item very often, due to low grades,
intervals on this item are going to be low, but the number of repetition grows fast.
Think about it:
Easy-to-remember elements will have a small 'number of repetitions' combined
with a comparetively large interval.
So, we don't need to give the ANN yet another data/variable, the ANN itself can learn
(taking 'number of repetitions' and 'current interval') what the difficulty
of an item is.
The problem is only in the beginning, on the first repetition: the ANN doesn't have
any data
about an element's difficulty. But then, neither do any other repetition
algorithms! We only have the first grade to start with.
(BTW: If a user will treat the first grade as "element difficulty"
the ANN will perfectly learn to use that information as "element difficulty".)
So then, taking only these 3 needed variables:
and giving the ANN feedback (output: next ideal interval), the ANN can learn to predict the output, based on these 3 inputs.
But how we can teach/train the ANN based on a user's learning process? On repetitions: if grade == 4 (good grade) we know that last interval was OK, so we can reinforce that ANN knowledge by adding it to the "ANN learning data":
If on the other hand the current grade is low (e.g. 2), it means that the last interval the ANN gave was too long, so we should shorten it (meaning: teach the ANN to give a shorter interval, given the same data), so we give NN the following learning data:
Everything above is very nice in theory. In practice there is a serious problem with items that are reviewed either at a later time or (since Memaid 0.4.0) earlier than than scheduled by ANN. (because since MemAid 0.4.0 - there is also a "Force ahead of scheduled time repetitions" feature).
The solution is quite simple and introduced in MemAid-0.4.0: to the above 3 inputs we add yet another: "real interval" since last repetition. (before MemAid-0.4.0 "last_interval" was basically equal to "last_interval_computed_by_ann"). This way the ANN can learn to cope perfectly even with these reviews that are not done on the "right day".
--
David Calinski
Back to Index